A multimodal generative AI model achieved high diagnostic accuracy and showed clinical value in preliminary reporting of chest x-ray images, according to research published March 25 in Radiology.
A team led by Eun Kyoung Hong, MD, PhD, from Brigham & Women’s Hospital in Boston, MA, found that their domain-specific model could detect conditions such as pneumothorax and subcutaneous emphysema and achieved a high rate of reports accepted without modification from radiologists.
“This could positively influence the efficiency of the radiologic interpretation workflow,” the Hong team wrote.
Radiology researchers continue to explore ways that generative AI, such as ChatGPT, could improve workflows by completing non-patient-facing tasks like writing reports. With the emergence of multimodal generative AI models, the researchers noted that AI models must be consistent with clinical goals. They added that deep learning’s impact on reducing radiologist workload, speeding up report generation, and making way for fast diagnosis remains to be fully studied.
Hong and colleagues developed a domain-specific multimodal generative AI model. For the study, they evaluated the model’s diagnostic accuracy and clinical value for providing preliminary interpretations of chest x-rays before radiologists saw the images.
For training, the team used consecutive radiograph-report pairs from frontal chest x-ray exams collected between 2005 and 2023 from 42 hospitals. The trained domain-specific AI model generated radiology reports for the radiographs. The test set included public datasets and images excluded from training.
The team also calculated the sensitivity and specificity of the model-generated reports for 13 radiographic findings and compared them with radiologist annotations. Four radiologists evaluated the subjective quality of the reports.
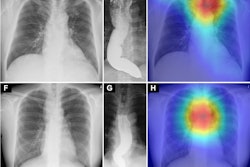
 Examples of frontal chest x-rays and associated reports generated by a domain-specific AI model, radiologist, and GPT-4Vision (GPT-4v, OpenAI). (A) The report generated by the domain-specific AI model proposes a diagnosis of advanced metastatic disease, the radiologist report suggests miliary Koch tuberculosis, and the GPT-4Vision report proposes potential pulmonary edema or infection as diagnoses. All three of the radiologists involved in establishing the reference standard for this radiograph reported pulmonary metastasis as the most likely diagnosis. (B) The report generated by the domain-specific AI model accurately detects a left clavicle fracture (arrow) but also erroneously suggests a left pneumothorax. The radiologist and GPT-4Vision reports do not mention these findings, instead describing the lung fields as clear with a normal cardiac silhouette and mediastinum. Of the three radiologists involved in establishing the reference standard for this radiograph, two confirmed the clavicle fracture, while none reported a pneumothorax. The model-generated report also mentions a CT scan, which represents a hallucination, since CT images were not provided as input. (C) The report generated by the domain-specific AI model identifies the presence and location of an endotracheal tube, esophagogastric tube, and right peripherally inserted central catheter. The report also notes mild pulmonary vascular congestion and a left basilar consolidative opacity, while the radiologist report notes pleural effusion and consolidation. The GPT-4Vision report describes diffuse lung opacities and possible cardiomegaly, with no evidence of pneumothorax.RSNA
Examples of frontal chest x-rays and associated reports generated by a domain-specific AI model, radiologist, and GPT-4Vision (GPT-4v, OpenAI). (A) The report generated by the domain-specific AI model proposes a diagnosis of advanced metastatic disease, the radiologist report suggests miliary Koch tuberculosis, and the GPT-4Vision report proposes potential pulmonary edema or infection as diagnoses. All three of the radiologists involved in establishing the reference standard for this radiograph reported pulmonary metastasis as the most likely diagnosis. (B) The report generated by the domain-specific AI model accurately detects a left clavicle fracture (arrow) but also erroneously suggests a left pneumothorax. The radiologist and GPT-4Vision reports do not mention these findings, instead describing the lung fields as clear with a normal cardiac silhouette and mediastinum. Of the three radiologists involved in establishing the reference standard for this radiograph, two confirmed the clavicle fracture, while none reported a pneumothorax. The model-generated report also mentions a CT scan, which represents a hallucination, since CT images were not provided as input. (C) The report generated by the domain-specific AI model identifies the presence and location of an endotracheal tube, esophagogastric tube, and right peripherally inserted central catheter. The report also notes mild pulmonary vascular congestion and a left basilar consolidative opacity, while the radiologist report notes pleural effusion and consolidation. The GPT-4Vision report describes diffuse lung opacities and possible cardiomegaly, with no evidence of pneumothorax.RSNA
Final analysis included 8.8 million radiograph-report pairs for training and 2,145 x-ray exams for testing. These were anonymized with respect to sex and gender. The model achieved a sensitivity of 95.3% for detecting pneumothorax and 92.6% for detecting subcutaneous emphysema.
The acceptance rate among the four radiologists was 70.5% for model-generated reports, 73.3% for reports by other radiologists, and 29.6% for ChatGPT-4Vision reports, respectively.
The researchers also used five-point scoring systems for agreement and quality, with five indicating complete agreement or quality and one being a clinically important discrepancy. The model-generated reports achieved statistically higher median agreement and quality scores than reports generated by ChatGPT-4Vision.
| Performances of deep-learning AI model, ChatGPT-4Vision for agreement and quality deemed by radiologists | |||
|---|---|---|---|
| Measure | ChatGPT-4Vision | Deep-learning AI model | p-value |
| Median agreement score | 1 | 4 | < 0.001 |
| Median quality score | 2 | 4 | < 0.001 |
Finally, from the team’s ranking analysis, model-generated reports were most often ranked the highest (60%), while GPT-4Vision reports were most often ranked the lowest (73.6%).
The study authors highlighted that future research will use prospective study designs and more diverse case complexities. They added that such research will focus on the interpretability and usability of different model-generated reports in real clinical settings.
“Additionally, using a larger pool of radiologists with diverse training experience in evaluating the model-generated reports would help assess the AI model’s generalizability across different expertise levels and subspecialty training,” they wrote.
In an accompanying editorial, Brent Little, MD, from the Mayo Clinic in Jacksonville, FL wrote that while the results of the study are “impressive,” he suggested that designers of generative AI systems might want to consider the possibility of creating a “report of the future.” This would improve, rather than emulate, current reports upon which systems are usually trained, he wrote.
“Such reports might incorporate graphic outputs, structured narrative reporting, and quantitative or semiquantitative severity scoring,” Little wrote, adding that the performance of these AI systems will likely improve rapidly and thoughtful discussions will be needed to find out how generative AI reporting systems can improve the work of radiologists.
The full study can be accessed here.