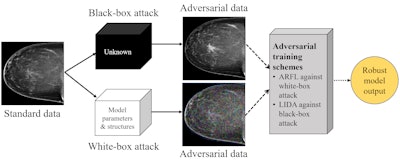
Methods for training artificial intelligence (AI) diagnostic algorithms can help prevent these models from producing medical errors caused by adversarial attacks, according to research presented at RSNA 2023 in Chicago.
A test of two security techniques developed at the University of Pittsburgh suggested that efforts to make medical machine-learning diagnosis models resilient to attacks could improve patient safety and prevent fraud. The work presented at RSNA builds on previous research that investigated the feasibility of adversarial attacking (black-box type), in which data generated by generative adversarial networks (GANs) are inserted into the image as either positive- or negative-looking adversarial image features.
Adversarial attacks on medical AI image classifiers are problematic because they can fool both the diagnosis model and radiologists themselves. Motivations for adversarial attacks on medical AI can range from unsafe diagnosis to insurance fraud to influencing clinical trial results.
 Degan Hao (left) and Shandong Wu, PhD (right), University of Pittsburgh.
Degan Hao (left) and Shandong Wu, PhD (right), University of Pittsburgh.
For the RSNA presentation, leading author Degan Hao and corresponding senior author Shandong Wu, PhD, highlighted the specific vulnerabilities of medical machine-learning diagnostic models. Simply adding adversarial noise to standard image data produces adversarial data from which a machine-learning diagnostic model will make a wrong diagnosis, according to the researchers.
Security strategies
Toward protecting these AI models against adversarial attacks, University of Pittsburgh researchers developed two novel defense strategies within the context of breast cancer diagnosis.
“Currently, numerous medical imaging-based AI diagnostic models have been developed for breast cancer with many under clinical evaluation and deployment,” explained Wu, director of the university's Intelligent Computing for Clinical Imaging Lab and also the Pittsburgh Center for AI Innovation in Medical Imaging. “Breast cancer imaging AI diagnosis is spearheading the field and there are more data available, so it is a better disease context to perform this study.”
Using 4,346 mammogram images, Hao, Wu, and colleagues used a strategy called adversarial training to defend against two types of adversarial attacks presented in the images:
1. White-box attack: Attackers know about AI model parameters. Adversarial data produced by projected gradient descent were used to insert noises into mammogram images.
To defend against the white-box attack, the researchers designed a “regularization algorithm” to facilitate what they call adversarially robust feature learning (ARFL). With ARFL, models are trained with a mixture of standard clean data and adversarial samples.
2. Black-box attack: Attackers have no access to AI model parameters. Adversarial data produced by GANs were used to intentionally insert positive- and negative-looking adversarial image features.
The team found that routine adversarial training with GAN-generated samples can lead to the issue of “label leakage,” a phenomenon that falsely inflates model performance and should be avoided in machine learning, Wu said. To resolve this label leakage issue and to defend against the black-box attack, the researchers designed a scheme they called label independent data augmentation (LIDA). This technique enabled the model to latch on to true classification features.
Vulnerabilities
In testing, the researchers found that standard training is vulnerable to black-box attacks.
| Figure 1: RESULTS: DEFENDING AGAINST BLACK-BOX ATTACKS |
||
|---|---|---|
| TEST AUC, % |
||
| Training Method |
Standard Test |
Adversarial Test |
| A. Standard training |
66.8 |
46.1 |
| B. Routine adversarial training |
41.2 |
99.9 |
| C. LIDA-based adversarial training |
63.0 |
63.7 |
| MODEL PERFORMANCE COMPARISONS |
||
In addition, the extremely high area under the curve (AUC) of 0.999 for routine adversarial training verified the label leakage issue that led to a falsely high AUC. In contrast, LIDA achieved an improved performance when testing on adversarial data without sacrificing performance on standard data. By addressing the label leakage issue, LIDA can effectively maintain the model’s performance when facing either standard or adversarial data, according to the researchers.
| Figure 2: RESULTS: DEFENDING AGAINST WHITE-BOX ATTACKS |
||
|---|---|---|
| TEST AUC (std), % |
||
| Training Method |
Standard AUC |
Adversarial AUC |
| A. Standard training |
69.2 |
58.8 |
| B. Routine adversarial training |
65.7 |
59.6 |
| C. ARFL-based adversarial training |
68.3 |
63.7 |
| D. Domain-specific batch normalization (DSBN) |
54.1 |
54.7 |
| E. Trading adversarial robustness off against accuracy (TRADES) |
63.7 |
63.2 |
| F. Multi-instance robust self-training (MIRST) |
63.0 |
63.6 |
| MODEL PERFORMANCE COMPARISONS, FIVE-FOLD VALIDATION |
||
While standard training and routine adversarial training again led to decreased AUC values when facing adversarial samples from white-box attacks (see Figure 2 above), the proposed ARFL method was able to bring the performance back to a high AUC while simultaneously maintaining a high AUC on standard data that was very close to performance achieved with standard training. Overall, ARFL also outperformed several other related methods, as shown in Figure 2.
“We also looked at feature saliency maps to analyze the effect of ARFL,” Hao said during the RSNA talk.
After examining feature saliency maps, the researchers were able to determine that ARFL models identified a greater number of sharply contrasted regions. This suggests that ARFL enhances the learning of discriminative features for diagnostic purposes, Hao added.
Security and safety
Wu told AuntMinnie.com that the security and safety of medical AI models could become a serious issue as they begin to deploy in the clinical environment. Models must not only maintain their accuracy but be resilient to potential cybersecurity attacks, including adversarial attacks.
“For black-box attacks, hackers could simply use publicly available data to train GAN models to perform attacks without access to the model parameters so it is an ‘easier’ setting to perform attacks,” Wu said. “Currently the risk of adversarial attacks is relatively low; part of the reason is that people still lack a good understanding of the vulnerabilities of AI/ML models to adversarial samples. But this could change over time, along with the wider deployment and use of such models in medical infrastructure and services.”
The University of Pittsburgh medical AI security study was limited in that it included data from one institution. The researchers now plan to test ARFL and LIDA in other medical imaging modalities.