Large language models (LLMs) can detect scoliosis on spine radiographs with accuracy up to 94% but struggle to identify lumbar spinal stenosis on MRI, according to a recent study.
The finding is from a test of five publicly available multimodal LLMs -- Grok 2, Grok 3, Grok 4, ChatGPT 4o, and Gemini 1.5 Flash -- on 171 spine x-rays and 200 lumbar MRI slices, with results suggesting the models could play a role in patient education, noted lead author Zachary Hoglund, a medical student at the University of Pennsylvania, and colleagues.
"Although promising for patient education in simple spine conditions, substantial advancements in accuracy and confidence metrics are essential prior to clinical adoption or broad patient utilization," the group wrote. The study was published May 2 in World Neurosurgery.
Patients are increasingly turning to commercial AI chatbots for medical information, with surveys suggesting more than 70% of U.S. respondents would consider using ChatGPT for self-diagnosis, according to the authors. Further, they cited statement by developers including Elon Musk who have publicly promoted generalist LLMs for medical image interpretation.
However, rigorous evaluation of their diagnostic accuracy across different imaging modalities and pathologies remains limited, particularly for musculoskeletal and spine conditions that heavily rely on imaging for diagnosis, they noted.
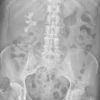
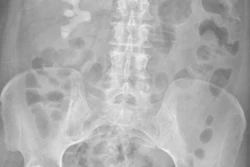
To further assess the models, the group collected 171 full-length anterior-posterior radiographs (100 with scoliosis, 71 normal) and 200 axial T2-weighted lumbar spine MRIs (100 with severe stenosis, 100 normal) from public databases. Each model was prompted identically with a yes/no question and asked to report its certainty as a percentage from zero to 100%. No examples or additional training were provided, and sessions were refreshed between queries to eliminate memory effects.
According to the results, outputs were divided significantly by condition. For scoliosis detection, Grok 4 led with 94.2% accuracy, followed by Gemini (91.2%), Grok 2 (89.0%), ChatGPT (64.3%), and Grok 3 (63.7%). For lumbar stenosis, Gemini performed best at 60.0%, followed by Grok 4 (57.5%), ChatGPT (54.5%), Grok 2 (50.0%), and Grok 3 (45.0%).
In addition, the group assessed the confidence the models expressed in their outputs, with ChatGPT the only model to consistently report lower confidence when it gave incorrect answers across both pathologies. The authors characterized this performance as “superior metacognitive capability.” In contrast, Gemini reported significantly higher confidence for its incorrect stenosis responses (p < 0.0001), which the authors suggested could pose meaningful risk for patients relying on the tools.
“LLMs show promise for future use as patient educational tools in more overt spine pathologies; however, significant caution must be provided to avoid patient harm by misdiagnosis in their current state, and LLM performance is not yet sufficient for clinical use,” the group wrote.
Future work may evaluate LLMs on multiplanar image views to better reflect clinical workflows, and prompt engineering may unlock greater diagnostic potential, the authors noted. They also identified image processing errors and confidence calibration as critical targets for improvement.
“Performance inconsistencies across model iterations underscore the necessity for specialized 25 medical imaging training,” the group concluded.
The full study is available here.












![Representative example of a 16-year-old male patient with underlying X-linked adrenoleukodystrophy. (A, B) Paired anteroposterior (AP) chest radiograph and dual-energy x-ray absorptiometry (DXA) report shows lumbar spine (L1 through L4) areal bone mineral density (BMD). The DXA report was reformatted for anonymization and improved readability. The patient had low BMD (Z score ≤ −2.0). (C) Model (chest radiography [CXR]–BMD) output shows the predicted raw BMD and Z score in comparison with the DXA reference standard, together with interpretability analyses using Shapley additive explanations (SHAP) and gradient-weighted class activation maps. The patient was classified as having low BMD, consistent with the reference standard. AM = age-matched, DEXA = dual-energy x-ray absorptiometry, RM2 = room 2, SNUH = Seoul National University Hospital, YA = young adult.](https://img.auntminnie.com/mindful/smg/workspaces/default/uploads/2026/04/ai-children-bone-density.0snnf2EJjr.jpg?auto=format%2Ccompress&dpr=2&fit=crop&h=167&q=70&w=250)

