A group in Japan has provided clear evidence that so-called intrasource balance in COVID-19 chest x-ray data sets is vital to minimize the risk of poor performance of AI deep-learning models, according to a study published November 3 in Scientific Reports.
A group led by Zhang Zhang, PhD, of Tohoku University in Sendai, found that using an intra-source imbalanced dataset of x-rays caused a serious training bias, even though the data set had a good intercategory balance.
“Our study reveals that the [intrasource imbalance] of training data can lead to an unreliable performance of deep-learning models,” the group wrote.
When developing deep-learning AI models to detect COVID-19, researchers collect as much data as possible from different medical facilities to avoid the impact of intercategory imbalance (ICI), which means a difference in data quantity among categories.
However, due to the ICI within each medical facility, medical data are often isolated and acquired in different settings among medical facilities, and this is known as the intra-source imbalance (ISI) characteristic, the authors explained. Moreover, this imbalance can also impact the performance of DL models, yet has received negligible attention, they added.
Thus, the group aimed to explore the impact of the ISI on DL models by comparing a version of a deep-learning model that was trained separately by an intrasource imbalanced chest x-ray data set and an intra-source balanced data set for COVID-19 diagnosis.
One data set, called the Qata-COV19 data set, contained 3,761 COVID-19 positive images from five different public facilities and 3,761 negative x-ray images from seven other public facilities. In comparison, a second data set called the BIMCV data set contained 2,461 positive images and 2,461 negative CXR images from a single public facility.
In brief, the group used a cross-data set approach in which they trained a VGG-16 deep-learning model using the original images from the Qata-COV19 data set and then tested it on the images from the BIMCV data set.
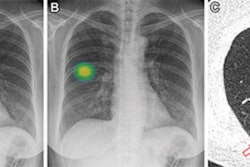
According to the findings, area under the curve (AUC) values were all larger than 0.99 when the VGG-16 model was trained and tested on the original images from Qata-COV19. Significantly, yet inexplicably, the model performed well even when lung regions were hidden in the Qata-COV19 images.
Conversely, the deep-learning model also performed well identifying disease in the BIMCV images, but when lungs were removed or boxed-out in these x-rays, the model's AUC values degraded significantly, according to the analysis.
“Such different results with different data sets demonstrate that the unreliable performance is related to the ISI,” the group wrote.
Ultimately, the study also demonstrates the fundamental “black-box problem” of deep learning, the authors noted. That is, although deep-learning models can achieve high performance on COVID-19 detection, there is a lack of lack transparency and explanation in how they achieve their predictions.
Without a sufficient understanding of the machine-made predictions, it becomes very complicated to detect errors in models’ performance and therefore, the reliability of deep learning models remains a concern, they wrote.
“Our study revealed a risk of training bias when using an intra-source imbalanced dataset, so researchers should raise their concerns about the intra-source balance when collecting training data to minimize the risk of unreliability,” the group concluded.
The full article is available here.