
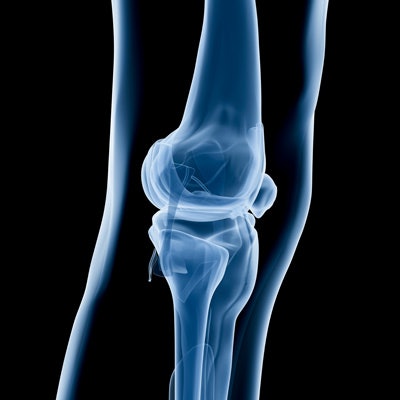
Supported by machine-learning technology, researchers have developed a natural language processing (NLP) algorithm that successfully automates classification of MRI knee scans to better understand MRI utilization, according to a study in the April issue of the American Journal of Roentgenology.
One key finding from the study is that the algorithm recorded "excellent accuracy" results on two separate databases of more than 2,000 MRI knee scans initially created in free-text formats at both Duke and Stanford universities. The results indicate that the NLP technology can be used successfully at other imaging centers to help reduce unnecessary imaging scans, according to the researchers (AJR, April 2017, Vol. 208:4, pp. 750-753).
"The medical record is critical and so important for decision-making, utilization questions, and policy; you can't get at that information without a system to organize and structure it," said study co-author Dr. Matthew Lungren, an assistant professor of pediatric radiology at Stanford. "This is another example of how machine-learning technology can benefit projects like this and move the ball forward."
Machine-learning potential
Natural language processing has become a kind of catch-all term that refers to a broad array of machine-learning technologies, Lungren said. The lure of machine learning is its potential to automate the amalgamation and analysis of disparate forms of imaging reports -- much of which is in narrative free-text formats -- through natural language processing and other techniques.
"The fundamental problem is you have a lot of potentially valuable data about imaging that relates to all kinds of areas within healthcare and cuts across many specialties," he said. "This data is either stored as an image with the accompanying expert's decision or discussion in text."
 Dr. Matthew Lungren from Stanford University.
Dr. Matthew Lungren from Stanford University.In addition, the radiology reports have been housed in an unstructured format and do not necessarily follow a standard template. Rather than review hundreds, thousands, or even millions of reports to extract information that can be structured and used for analysis, an NLP system could view the data more quickly and efficiently and target sought-after information.
The interest in connecting NLP technology with knee MRI reports stems from a 2011 study co-authored by Lungren that found that orthopedic physicians with a financial interest in MRI equipment tended to order more imaging studies and have higher rates of negative exams. While there is the obvious conflict of interest, on a more micro level, an imaging center could use an NLP algorithm to hone in on the detected imbalance, correct the discrepancy, and ensure that patients receive an appropriate scan.
"If a clinician knew the rate of negative or inconsequential exams was outside the standard deviation for people in their field, that is someone -- potentially through education, protocols, or policies -- the hospital could rein in to a more reasonable area for imaging appropriate use and utilization," Lungren said. "That's a win that could be based off an algorithm like [NLP] that can seamlessly look through imaging reports and text and draw conclusions about the studies being ordered and all the patients being referred."
In this endeavor, the researchers created an NLP algorithm that uses terms and patterns in free-text narrative MRI knee reports. The goal is to identify normal and abnormal cases automatically on the basis of a previously published manual classification scheme and test the application on new unseen knee MRI results.
The database in the study contained 706 knee MRI reports from a 12-month period beginning in January 2011 from Duke and 1,748 knee MRI reports from a two-year period beginning in January 2008 from Stanford. The researchers included only first-time knee MRI scans from patients with no history of knee surgery to control for confounding effects of prior surgery and postoperative changes.
MRI scans were considered positive if the results included at least one of the following diagnoses: tears of the anterior cruciate ligament, posterior cruciate ligament, or meniscus; injury to the medial collateral ligament, lateral collateral ligament, or patellofemoral extensor mechanism; or an osseous defect.
NLP construction
To build the NLP algorithm, the researchers randomly divided the radiology reports from both universities into a training set that contained 80% of the reports and a test set that included the remaining 20% of the reports. Radiology reports were modeled in the training set as vectors to create a support vector machine (SVM) framework, which in turn was used to train the NLP system on how to classify the data.
One key component of the NLP algorithm's evaluation was the creation of a separate test at Duke and at Stanford to ensure that the technology could be effective at different institutions. Thus the researchers evaluated the performance within and across both organizations to ensure the reproducibility of the SVM system.
"The big question that everyone will have is: We have an algorithm that works great on our data, but my radiologist at Stanford, or Duke, or St. Elsewhere may see things differently. Will your algorithm be able to do the same kind of work on my data as it does on your data?" Lungren said. "If we just develop technology that only works at our institution, we lose out on the opportunity to make it generalizable."
NLP evaluations
The researchers then turned the algorithm loose to see how well it classified reports as positive or negative. It achieved an accuracy of 88% (range, 82%-94%) at Duke and an accuracy of 87% (range, 80%-93%) at Stanford.
When they swapped training and test sets and analyzed the NLP algorithm at opposite facilities, Duke's training set reached an accuracy of 74% (range, 65%-82%) using the Stanford test. The Stanford training set achieved an accuracy of 85% (range, 78%-92%) using Duke's test set.
The machine-learning classifier "did not achieve perfect accuracy," the group wrote. "However, the accuracy measures are comparable to those of other published NLP studies."
Still, the results showed "excellent accuracy" for the NLP systems to classify radiology reports, Lungren and colleagues concluded, and they support the ability to reproduce its efficacy at different imaging centers.
"We are at a turning point where deep learning is exploding and machine-learning technology can benefit projects like this," Lungren said. "What would've taken at least five years of work to get the terms defined for a specific type of report only took a fraction of the time and effort thanks to the developments in machine learning."
As for next steps, the Duke and Stanford researchers hope to soon publish their latest data showing accuracy of greater than 95% with NLP technology.
"We are moving the ball forward again and this work is just the first shot over the bow," he added. "We are hoping to use it for all of our deep-learning projects as well as some of our predictive imaging and population precision health."
.fFmgij6Hin.png?auto=compress%2Cformat&fit=crop&h=100&q=70&w=100)




.fFmgij6Hin.png?auto=compress%2Cformat&fit=crop&h=167&q=70&w=250)










