The verdict is out on artificial intelligence versus radiologists when it comes to reading images, but both can be fooled if images have been tampered with, according to research published December 14 in Nature Communications.
A team that included first author Qianwei Zhou, PhD, from the Zhejiang University in China and senior author Shandong Wu, PhD, from the University of Pittsburgh found that an AI model was fooled by over two-thirds of fake breast images, making them prone to cyberattacks and highlighting the need for safety measures in AI.
"From a diagnosis perspective, the imaging characteristics of the diagnosis-sensitive contents are of particular relevance and importance for researchers and clinicians towards building robust and safe medical imaging diagnosis AI systems," Wu told AuntMinnie.com.
AI's potential for breast cancer detection as a second reader has grown in recent years, with research suggesting that both can coexist in clinical settings.
However, AI is also at risk for cyberattacks, such as attacks based on generative adversarial network (GAN) algorithms. Imperceptible noises can be added to images, new images can be added to replace true images, or targeted modifications can be made to true images. The researchers said these attacks can lead to unexpected, false, or wrong diagnostic results when tampered images are fed to an AI model.
Zhou et al wanted to find out how AI would behave under these complex adversarial attacks, using mammogram images to develop a model for detecting breast cancer. The study authors called it a "critical test" for AI's safety evaluation of plausible adversarial attacks.
"Understanding the behaviors of an AI diagnostic model under adversarial attacks will help gain critical insights on identifying cybersecurity vulnerabilities and on developing mechanisms to potentially defend such attacks," they wrote.
The team trained a deep-learning algorithm to distinguish cancerous and benign cases with more than 80% accuracy. The group also developed a GAN algorithm that inserted or removed cancerous regions from negative or positive images. The AI model then classified these adversarial images.
Zhou and colleagues found that the model was fooled by 69.1% of the fake breast images. Of the 44 positive images made to look negative by the adversarial network, 42 were classified as negative by the model. Of the 319 negative images made to look positive, 209 were classified as positive.
The results were compared with those of five radiologists who were asked to distinguish fake mammograms from real images. They had an accuracy that ranged between 29% and 71%, depending on the radiologist.
"The participating radiologists of the study were very surprised by the results and how medical diagnosis AI could potentially be interfered with," Wu said.
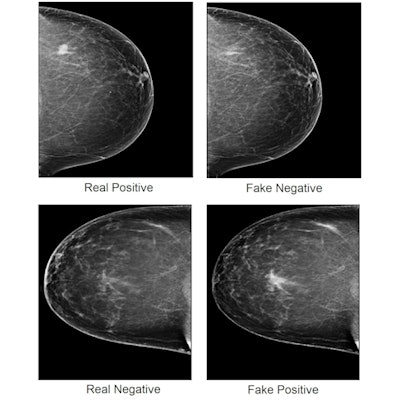
 Mammogram images showing real cancer-positive (top left) and cancer-negative (bottom left) cases, with cancerous tissue indicated by white spot. A generative adversarial network program removed cancerous regions from the cancer-positive image, creating a fake negative image (top right) and inserted cancerous regions to the cancer-negative image, creating a fake positive (bottom right). Image courtesy of Qianwei Zhou, PhD, et al., Nature Communications.
Mammogram images showing real cancer-positive (top left) and cancer-negative (bottom left) cases, with cancerous tissue indicated by white spot. A generative adversarial network program removed cancerous regions from the cancer-positive image, creating a fake negative image (top right) and inserted cancerous regions to the cancer-negative image, creating a fake positive (bottom right). Image courtesy of Qianwei Zhou, PhD, et al., Nature Communications.Wu told AuntMinnie.com that the team is starting to work on developing potential defense methods and strategies against adversarial attacks in the medical imaging domain. The authors wrote that human experts remain "a key role" at this stage in detecting suspicious adversarial inputs. However, they added that educational interventions and tools are in "great need."
"Our experiments showed that highly plausible adversarial samples can be generated on mammogram images by advanced generative adversarial network algorithms, and they can induce a deep learning AI model to output a wrong diagnosis of breast cancer," they said.